Hồi quy logit đa bậc – STATA
Giới thiệu về hồi quy logit đa bậc
Hồi quy logit đa bậc (Multinomial logistic regression) được sử dụng để ước lượng mô hình với biến phụ thuộc dạng danh mục (không thứ tự), trong đó log của odds là sự kết hợp tuyến tính của các biến giải thích. Hồi quy logit đa bậc tương tự như hồi quy logit thứ tự, tuy nhiên, không đòi hỏi vị trí thứ tự của các nhóm trong biến phụ thuộc.
Xem thêm: Hồi quy logit thứ tự
Để hiểu rõ hơn về hồi quy logit đa bậc, các bạn tìm hiểu thông qua các ví dụ sau:
- Việc chọn nghề của cá nhân có thể bị ảnh hưởng bởi nghề nghiệp và học vấn của cha mẹ. Giả sử chúng ta muốn nghiên cứu về mối quan hệ giữa việc chọn nghề với mức học vấn và nghề nghiệp của người cha. Ở đây, biến chọn nghề là biến phụ thuộc dạng danh mục nhiều mức.
- Một nhà sinh vật học muốn nghiên cứu về loại thức ăn yêu thích của loài cá sấu. Các con cá sấu lớn nhiều khả năng sẽ có những thức ăn yêu thích khác với các con nhỏ. Biến phụ thuộc trong nghiên cứu này là các loại thức ăn (biến danh mục không thứ tự) và biến giải thích là kích cở cá sấu, và những biến môi trường khác.
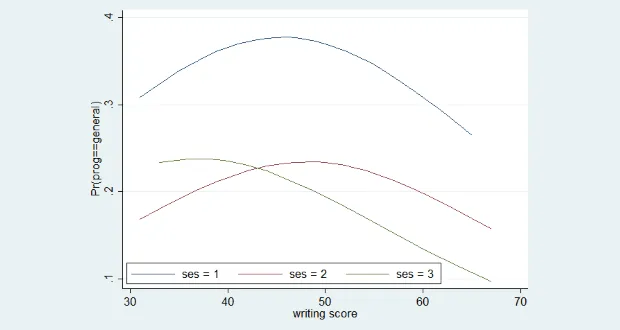
- Chúng ta muốn nghiên cứu ảnh hưởng đến việc chọn ngành đăng ký dự thi đại học của các học sinh PTTH. Giả sử có 3 ngành được đăng ký bao gồm hướng nghiệp, học thuật, tổng quát được tổng hợp trong biến ngành học. Biến phụ thuộc ở đây là ngành học với 3 nhóm. Các biến giải thích có thể bao gồm như điểm số viết và những yếu tố kinh tế xã hội liên quan đến các học sinh.
Bài viết này trình bày về vấn đề hồi quy đối với biến phụ thuộc dạng danh mục, còn gọi là hồi quy logit đa bậc. Các hướng dẫn thực hành sẽ được minh họa theo ví dụ 3 nêu trên.
1.Thống kê về dữ liệu sử dụng
Phần minh họa sử dụng dữ liệu thực hành là mlogit.dta
use https://www.vietlod.com/data/mlogit.dta, clear
Bộ dữ liệu bao gồm 3 biến prog ses write với 200 quan sát. Thông tin cụ thể của các biến như sau:
- Biến prog là ngành học, có dạng danh mục với 3 giá trị: 1 (tổng quát), 2 (học thuật) và 3 (hướng nghiệp).
- Biến ses cho biết điều kiện kinh tế xã hội, là biến danh mục thứ tự với 3 múc 1 (thấp), 2 (trung bình) và 3 (cao).
- Biến write là điểm thi viết, là 1 biến liên tục.
tab prog ses, chi2

table prog, con(mean write sd write)

Lựa chọn phương pháp phân tích
- Hồi quy probit đa bậc: tương tự như hồi quy logit đa bậc nhưng yêu cầu sai số phần dư có phân phối chuẩn.
- Phương pháp phân tách nhiều nhóm
- Hồi quy logit đa bậc, có nhiều nét tương đồng với hồi quy logit thứ tự. Tuy nhiên, trong hồi quy logit đa bậc thì yếu tố thứ tự được bỏ qua. Điểm hạn chế chung của 2 phương pháp này là các kết quả hồi quy được thực hiện trên các nhóm dữ liệu khác nhau. Đồng thời cả hai đều thực hiện hồi quy trên 2 nhóm không bị ràng buộc bởi điều kiện tổng mức xác suất của các nhóm bằng 1. Thông thường tổng mức xác suất của các nhóm sẽ lớn hơn 1. Tuy nhiên, nếu chúng ta mã hóa để biến đổi giá trị của biến phụ thuộc thành 2 nhóm thì sẽ không khai thác hết thông tin, do vậy, kết quả hồi quy logit sẽ không hiệu quả.
- Hồi quy logit thứ tự: được ưu tiên sử dụng thay thế hồi quy logit đa bậc khi biến phụ thuộc dạng danh mục được sắp xếp thứ tự. Nghĩa là có sự phân biệt thứ tự ở các nhóm giá trị của biến phụ thuộc. Khi đó, kết quả hồi quy logit sẽ tin cậy và hiệu quả hơn.
Còn tiếp…
Khi em chạy logistic bằng STATA thì có 1 câu lệnh . mfx để cho ra giá trị dx/dy mà em cần biết. Vậy nếu dùng SPSS thì có cú pháp nào tương tự câu lệnh đó không và nếu có thì làm như thế nào ạ? Em cám ơn!
Không giống như Stata, SPSS không có sẳn công cụ để tính tác động biên của hồi quy logit. Tham khảo: Tác động biên trên SPSS.
Do vậy, bạn phải tính tác động biên này bằng tay theo định nghĩa là phần xác suất (hoặc log của odds hoặc odds ratios) tăng lên/giảm xuống khi X thay đổi 1 đơn vị. Để dễ hiểu và trực quan hơn bạn nên thể hiện các động biên này bằng đồ thị. Tất cả những tính toán này SPSS sẽ thực hiện giúp bạn.
Theo ý kiến của tôi, bạn đã biết hồi quy logit cũng như tính tác động biên trên Stata thì tiếp tục thực hiện trên Stata, lý do gì phải sử dụng SPSS?
Em cám ơn Thầy rất nhiều!